TLDR:
- Synthetic data solves data bottlenecks: It reduces the time and cost of collecting and labeling data—particularly rare edge cases—which often consume the majority of AI development time.
- Complex scenes remain challenging: Dynamic environments, multi-agent behaviors, and multi-sensor fusion are still hard to simulate with full real-world accuracy.
- Fidelity vs. scalability is a trade-off: Higher visual and physical fidelity boosts sim-to-real transfer, but it comes at significant computational cost. Hybrid strategies—such as blending synthetic with real data or tuning realism by task—are emerging to balance scalability and accuracy.
- New tech is bridging the reality gap: Generative Adversarial Networks (GANs) enhance texture realism, procedural modeling automates diverse scene creation, reinforcement learning (RL) agents simulate realistic behaviors, and closed-loop simulations enable continuous feedback for realism—together narrowing the sim-to-real gap.
the future of “seeing”
Deep learning has driven remarkable progress in computer vision tasks such as object detection, semantic segmentation, and 3D scene understanding for applications like autonomous vehicles, drones, and industrial robots. Real-world datasets like COCO, KITTI, and the Waymo Open Dataset have enabled these breakthroughs by providing large-scale labeled examples.
However, they remain expensive, labor-intensive, and inherently incomplete because they rely on passive data collection from real-world environments. As a result, they often fail to capture rare edge cases or long-tail scenarios, like unusual lighting conditions, unexpected obstacles, or atypical pedestrian behaviors, which are critical for building truly robust perception systems.
The scale of this challenge is significant. According to a 2024 Cognilytica report, up to 80% of an AI project’s timeline—across domains like natural language processing, predictive analytics, and computer vision—is consumed by data preparation. Much of this effort is dedicated to manual collection, cleaning, curation, and annotation of real-world datasets. This persistent data bottleneck slows iteration cycles, drives up development costs, and ultimately limits model generalization.
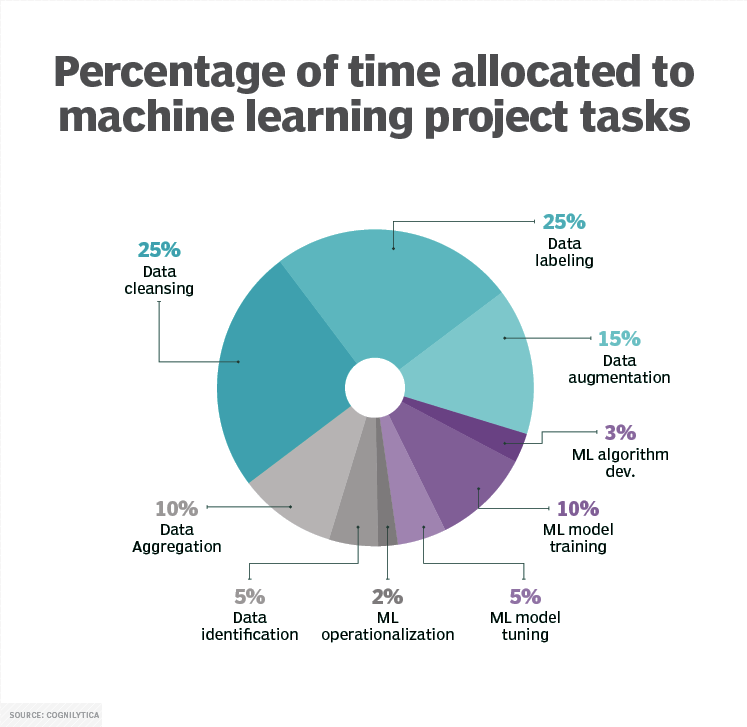
Synthetic data offers a compelling alternative. By procedurally generating large-scale, perfectly labeled datasets, teams working in domains like urban autonomous driving or warehouse robotics can bypass much of the manual overhead while controlling for critical variables such as lighting, occlusion, and object variation. It’s no surprise the synthetic data market is rapidly expanding; MarketsandMarkets projects it will grow to $2.1B by 2028.
However, generating synthetic data that meaningfully improves real-world performance is far from trivial. For perception models, the core challenge lies in accurately simulating complex visual phenomena such as material reflectance, weather conditions, sensor noise, and motion blur that are critical for robust generalization. Without these nuances, models trained on synthetic data often suffer a “reality gap,” a drop in performance when transferring from synthetic environments to real-world deployment domains, ultimately limiting their effectiveness in production systems.
Replicating the Full Complexity of Dynamic Scenes
For advanced computer vision tasks such as action recognition, multi-object tracking, or scene understanding, accurately simulating dynamic environments with multiple interacting agents is critical. These tasks are particularly sensitive to the fidelity of dynamic scenes because they rely on temporal consistency, realistic motion patterns, and accurate agent behavior prediction to generalize effectively. Yet, modeling these environments at scale introduces significant computational and algorithmic challenges.
Dynamic scenes involve nonlinear dependencies—the movement of one agent can influence the trajectories of others, creating cascading visual effects such as occlusion chains, where one moving object repeatedly blocks others, or motion blur spreading across interacting agents. A 2023 Nature study highlighted that most simulation frameworks struggle with emergent behaviors, such as a pedestrian abruptly changing direction in response to another agent’s motion—actions that appear irrational or unpredictable from a purely physics-driven perspective. Yet, these behaviors are exactly the kind that a robust perception system must handle to avoid failure in real-world deployments.
This complexity becomes especially apparent in high-stakes applications:
autonomous driving
In self-driving scenarios, edge cases like a multi-car pile-up or a pedestrian suddenly darting into traffic may account for less than 1% of total driving miles, yet they are disproportionately responsible for perception failures. Autonomous vehicles average fewer than 10 accidents per million miles, yet those rare edge cases still dominate critical safety incidents.
Beyond simply detecting objects, the model must interpret how traffic flow changes after an anomaly, such as unusual trajectories, stopped vehicles in unexpected lanes, or human drivers taking evasive maneuvers. These scenarios are often framed as intent estimation or behavior prediction tasks, where the system must anticipate how agents will respond to evolving conditions to ensure safe and reliable decision-making.
sports analytics
In sports analytics, the challenge lies in simulating the chaotic, highly dynamic interactions between players. This goes beyond simple object tracking, requiring models to learn team strategies and tactics by reasoning about intent, coordination, and adaptive decision-making.
But this problem isn’t unique to sports. Many real-world environments are multi-layered and sensor-rich, such as industrial and warehouse robotics, where autonomous systems must similarly interpret complex interactions across multiple modalities to coordinate effectively.
Multi-Sensor Interaction Under Varied Environmental Conditions
Modern perception systems, especially robotics and autonomous vehicles, rarely rely on a single sensor. Instead, they fuse data from cameras, LiDAR, radar, and even thermal sensors to build a coherent, robust representation of the environment. Simulating this multimodal data with high fidelity is far more complex than simply generating realistic images, as it requires accurately modeling cross-sensor correlations, noise characteristics, and temporal alignment. This stands in sharp contrast to traditional vision-only synthetic pipelines, which focus solely on photorealistic imagery and overlook the additional challenges of sensor fusion.
For cameras, you need to go beyond surface-level rendering and account for the physics of light transport to accurately simulate shadows, reflections, and material properties. Without this level of realism, important visual cues like glare on glass, subsurface scattering in skin, or soft shadow gradients can be lost, reducing the fidelity of the synthetic data. Capturing these nuances is essential to ensure perception models trained on synthetic imagery can generalize effectively to real-world conditions.
For LiDAR, a physically accurate simulation must model beam divergence, signal attenuation, and Mie scattering caused by fog, rain, or dust. These effects introduce unpredictable noise and can cut LiDAR detection ranges by more than 50% in heavy precipitation. While simulators like CARLA or AirSim provide basic LiDAR modeling, many do not fully capture these complex environmental effects, which can lead to perception failures such as missing low-contrast obstacles or misjudging distances when deploying models in poor weather conditions.
For radar, high-fidelity simulation requires modeling the Doppler effect, multi-path reflections, and material-dependent absorption to generate realistic velocity and range data. However, realistic radar simulation remains challenging due to a lack of mature open-source tools and limited availability of labeled datasets for validation, which hampers the ability to train and benchmark robust radar-based perception models.
This becomes especially critical in applications like:
autonomous navigation
Imagine training a self-driving car to handle a heavy rainstorm. The system must process synchronized camera, LiDAR, and radar data streams, even though each sensor is degraded in different ways. Visual contrast drops, LiDAR returns become noisy, and radar may struggle with fine-grained object separation.
Generating synthetic data that reflects these coupled degradations is still an open problem, further complicated by the difficulty of synchronizing and fusing these noisy signals into coherent training data for multimodal perception models.
robotics
For robotic manipulation, simulating how a vision system perceives semi-transparent or glossy objects involves modeling the intricate interplay of light, reflection, and refraction. Standard graphics pipelines often fail to capture these subtle but crucial cues, which affects not only object perception but also grasp stability prediction and leads to unreliable planning and execution in real-world scenarios.
Capturing Biological and Organic Complexity
If simulating urban traffic and industrial environments is hard, organic and biological scenes add another level of complexity. In fields like medicine and agriculture, perception systems must interpret highly variable, often soft and deformable structures. Unlike the more structured and discrete variability of urban scenes, biological variation is continuous and high-dimensional, spanning differences across individuals, species, or growth stages. This immense diversity makes it exceptionally difficult to create synthetic datasets that truly generalize.
Medical Imaging
Generating realistic synthetic medical data is extremely challenging. Anatomical variation across populations is vast, and rare diseases introduce subtle visual markers that are poorly represented in real-world datasets. Simulating these subtle textures, densities, and pathologies in modalities like CT or MRI scans while maintaining clinical relevance requires not just graphics expertise but also deep domain-specific medical knowledge. As a result, synthetic data generation in this domain often requires close co-development with radiologists or other medical experts to ensure accuracy and clinical utility.
Agriculture
Training drones for crop monitoring requires modeling the complex appearance of plants across different growth stages, lighting conditions, and weather patterns. Even the same crop can look drastically different under morning sunlight, midday glare, or twilight haze. Add seasonal changes, soil variation, and pest damage, and the resulting diversity of visual states becomes almost impossible to fully simulate. Traditional image augmentation techniques, such as rotation or brightness shifts, often fail to capture this real-world diversity, leaving models poorly equipped for true field variability.
Ultimately, whether it’s a rainy highway, a crowded sports field, or a cancer screening dataset, the underlying problem is the same: the central open challenge in simulation-for-perception is how to generate synthetic data that captures both the physics of the environment and the subtle, high-dimensional variability of the real world.
“We’re using simulation to create massive
— Jensen Huang, NVIDIA CEO
amounts of synthetic data to train
AI models, enabling us to test and
refine autonomous systems in virtual
environments before they ever
touch the real world. This approach
accelerates development and
ensures robustness across
diverse scenarios.”
Computational Costs and Scalability
While synthetic data offers clear advantages in flexibility and coverage, high-fidelity simulation isn’t free. Achieving high fidelity, encompassing high-resolution imagery, physical realism in lighting and materials, and lifelike agent behaviors, requires substantial computational power. Generating photorealistic, dynamic scenes at scale can demand enormous resources, which often becomes a limiting factor when moving beyond small proof-of-concept datasets, such as limited robotics trials or a small selection of autonomous vehicle corner cases.
To simulate realistic environments, you’re not just generating visually appealing images; you’re modeling physics-based animation, photometric effects such as lighting and material reflectance, sensor-specific noise characteristics, and coordinated multi-agent, time-dependent behaviors. That means heavy reliance on GPU clusters, ray-tracing engines, and physics simulations, all of which scale poorly as you push toward more realism.
For example, generating a training-ready sequence of 1 million high-fidelity images with physics-based lighting and multi-agent interactions can easily consume 10,000–20,000 GPU hours, translating to tens of thousands of dollars in cloud compute costs—far beyond what’s practical for quick iteration.
Reports from firms like Gartner note that compute costs for high‑fidelity data generation are now a “significant consideration for ROI” in synthetic data pipelines. As Gartner explains in its February 12, 2024 report How to Calculate Business Value and Cost for Generative AI Use Cases, “experimenting can be done inexpensively for most use cases,” but “hidden costs” from resources—such as GPU clusters, tracing engines, and physics simulations—can add up quickly.
However, these simulation costs are often still lower than collecting and labeling real-world data at scale, especially for tasks like semantic segmentation, where manual annotation remains labor-intensive and expensive.
The scalability challenge becomes even more pronounced in certain domains:
Satellite and Aerial Imagery
Training vision models to detect objects in satellite imagery requires rendering vast, geographically accurate terrains. It’s not just about drawing a 3D landscape; simulating atmospheric effects, varying weather conditions, and lighting changes across time zones adds enormous computational overhead. Achieving consistent geospatial fidelity while maintaining visual realism is still a computationally expensive process, especially when aiming for sub-meter or even centimeter-level resolution needed for use cases like monitoring deforestation, analyzing traffic patterns, or assessing crop health at scale.
Manufacturing and Industrial Inspection
In manufacturing, subtle visual defects like tiny scratches, progressive wear, or material inconsistencies are often the hardest to detect. To simulate these for training, you need ultra-high-resolution rendering, advanced material shaders, and time-series degradation models that show how surfaces change or wear down over time.
Real-world use cases include circuit board inspection, where microscopic soldering flaws can cause failures, or automotive paint finish analysis, where barely visible blemishes impact quality control. Generating datasets that capture these nuanced changes on an industrial scale can quickly consume terabytes of storage and thousands of GPU-hours.
Urban-Scale Autonomous Driving
For self-driving cars, photorealistic simulation goes far beyond a single road segment. It must replicate entire cities filled with dynamic agents, from pedestrians and cyclists to both autonomous and human-driven vehicles, all interacting within complex traffic patterns and diverse weather conditions.
Rendering a single minute of high-fidelity driving simulation across multiple synchronized sensors (RGB, LiDAR, radar) can take hours of compute time if not optimized. Yet this scale is essential for regulatory safety testing and ensuring sufficient exposure to rare but safety-critical events, which may require hundreds of millions of simulated miles to achieve statistically significant coverage of corner cases. Scaling to that level of synthetic driving remains a major engineering challenge.
Trends and Technologies Advancing Synthetic Data for Computer Vision
Despite the computational and scalability challenges, a new wave of emerging technologies is reshaping how synthetic data is generated, validated, and deployed. Advances such as procedural content generation, learned simulators, and closed-loop simulation systems are enabling richer, more scalable, and more domain-specific datasets for training next-generation computer vision models.
Generative AI for Image Refinement
Generative models, particularly GANs (Generative Adversarial Networks) and diffusion models, have dramatically improved the realism of synthetic imagery. GANs excel at producing high-quality images quickly, making them ideal for speed-sensitive applications, while diffusion models generally achieve higher fidelity and diversity at the cost of longer generation times. According to Stanford’s AI Index Report, the quality and diversity of outputs from generative models have seen “remarkable progress” over the past few years.
Generative models can create realistic surface textures for 3D objects that might otherwise look too synthetic or generic. For example, a simple procedural concrete texture on a simulated building can be enhanced to show realistic weathering, stains, cracks, and surface variations that match real-world materials.
This is especially helpful for reducing the “uncanny valley” effect in synthetic datasets, where everything looks just slightly too clean or artificial. This approach extends far beyond buildings, applying equally well to domains such as adding subtle imperfections to facial skin textures or simulating road wear and vehicle rust—enhancements that improve visual authenticity across countless synthetic environments.
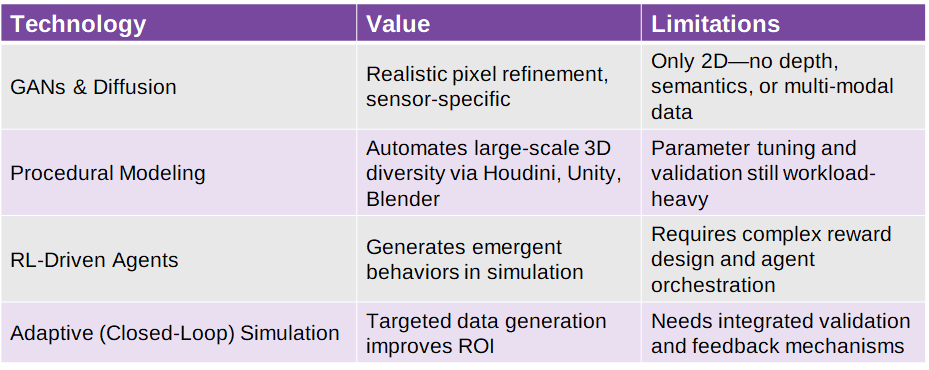
However, the key limitation remains that generative models are inherently 2D pixel-based. They don’t natively produce the multi-modal ground truth required for many perception tasks—whether geometric data like depth maps and LiDAR point clouds, semantic outputs such as class labels, or dynamic information like motion vectors. This makes them less suitable for depth-aware or geometry-aware vision systems, which are increasingly common in robotics and autonomous vehicles.
As a result, generative models are best used as a post-processing layer, refining or augmenting already-simulated data rather than replacing physics-based simulation. That said, emerging research is exploring ways to combine generative models with 3D representations and neural radiance fields (NeRFs) to bridge this gap, hinting at more integrated solutions in the future.
Procedural Modeling for Scalable Diversity
Procedural modeling uses algorithmic rules and stochastic processes, which introduce controlled randomness in aspects like layout, object placement, and visual appearance, to generate massively diverse 3D environments without manually designing each asset. This diversity is essential for preventing overfitting, where a model performs well only in a single static virtual world but fails to generalize to new object configurations, lighting conditions, or scene variations. By introducing variability at scale, procedural modeling helps ensure broader and more robust generalization.
Tools like Houdini, Unity Perception, and Blender’s procedural generation plugins can:
- Randomize building architecture, room layouts, or vegetation to create thousands of unique scenes.
- Vary lighting conditions, object placements, and textures on the fly.
- Introduce domain-specific artifacts (e.g., cluttered warehouses for robotics, varied urban road layouts for self-driving).
For those seeking open-source alternatives, platforms like Habitat-Sim provides scalable, physics-aware procedural generation tailored for robotics and embodied AI research.
By parameterizing every component of a scene, engineers can systematically vary critical factors such as lighting, geometry, and occlusion to generate edge-case-rich datasets, rather than relying on random sampling alone. This structured control enables more targeted coverage of rare but important scenarios without the need to manually author each variation.
A key use case involves automatically creating diverse indoor scenes—with different furniture layouts, wall finishes, and visual obstructions—to generate training data for mobile robot navigation and object detection capabilities. This directly supports tasks like indoor SLAM (simultaneous localization and mapping), room segmentation, and grasp planning, which are commonly evaluated on benchmarks such as AI Habitat or Matterport3D.
AI-Assisted Simulation with Reinforcement Learning
AI-generated behaviors are increasingly shaping synthetic data itself. Reinforcement learning (RL) agents can be deployed within simulation environments to produce emergent behaviors that better mimic real-world unpredictability. This enables continuous environment evolution, which is difficult to script manually, resulting in richer and more dynamic synthetic scenarios for training.
For example, RL-driven pedestrian agents can jaywalk, hesitate, or make seemingly irrational movement patterns, creating more realistic traffic scenarios for self-driving perception models. These behaviors are especially valuable for stress testing autonomous vehicle systems against rare but plausible human actions that are critical for safety.
Simulated drones can be controlled by RL policies that create non-deterministic flight paths, exposing aerial vision models to more diverse viewpoints. This is particularly useful for applications like surveillance, package delivery, and infrastructure inspection, where unpredictable flight dynamics help models better handle real-world variability.
This approach adds behavioral realism to synthetic worlds, complementing the geometric and photorealistic fidelity of traditional simulation. When RL-based agents are combined with procedural world generation, the result is not only visual diversity in the environment but also rich interactional diversity, creating synthetic scenarios that better reflect the complexity of real-world dynamics.
Real-Time Adaptive Simulations (Closed-Loop Data Generation)
One of the most promising trends is real-time adaptive simulation, where the synthetic data pipeline actively learns from the weaknesses of the target vision model. This approach is particularly valuable in domains where failure modes are rare but carry high risk, such as autonomous vehicles, drones, and other safety-critical robotic systems, ensuring the model is exposed to the most challenging scenarios before deployment.
This technique integrates active learning with simulation by:
- Analyzing failure cases in the current perception model—identified through tools like confusion matrices, error clustering, or runtime performance logs (e.g., misclassifications in low-light rain conditions).
- Dynamically generating more of those specific failure-inducing scenarios, targeting the model’s weakest points.
- Retraining the model on this focused dataset to close the performance gap.
This closed-loop approach ensures that compute resources are focused on generating high-value data—not just more random samples. By prioritizing failure-driven scenarios, it improves data efficiency and exemplifies model-guided simulation, where the model itself informs which synthetic data is most valuable for closing performance gaps.
Imagine an autonomous driving model that consistently struggles with detecting partially occluded cyclists in foggy conditions. The simulator would automatically generate thousands of new scenes with varying fog densities, occlusion angles, and cyclist behaviors to improve robustness. This targeted scenario generation can seamlessly feed into continual learning pipelines or online model adaptation, ensuring the model evolves and improves as new failure modes are discovered.
Benchmarking and Validation Frameworks
As synthetic data becomes more prevalent in computer vision pipelines, benchmarking and validation have become critical for quantifying its true value. The key question engineers face is: How well does a model trained on synthetic data generalize to real-world conditions? This validation is especially crucial in regulated or high-stakes domains such as healthcare, automotive, and other safety-critical applications, where performance failures can have serious consequences.
To answer this, the industry is converging on standardized validation frameworks that provide measurable metrics for sim-to-real transferability.
A common methodology is:
- Train the same model architecture on different synthetic datasets (or a mix of synthetic and real).
- Evaluate performance on a held-out, real-world benchmark test set, such as KITTI, Cityscapes, or COCO.
- Quantify the transfer gap, i.e., the drop in performance compared to a model trained exclusively on real-world data. In practice, these gaps can range from as little as 5% for well-modeled tasks to as much as 30% or more for complex perception challenges, depending on the task, sensor modality, and realism of the synthetic data.
This approach allows teams to systematically evaluate:
- Data fidelity – Does higher visual realism actually lead to better real-world generalization? Some studies show diminishing returns beyond a certain fidelity threshold, where additional realism yields little improvement despite significantly higher computational cost.
- Coverage vs. realism trade-offs – Does a procedurally generated but less photorealistic dataset still outperform a smaller, high-fidelity dataset? Greater coverage often comes at lower fidelity but offers higher scalability, making it more practical for broad scenario diversity.
- Hybrid data strategies – How much real-world data needs to be mixed with synthetic data to minimize the domain gap? Common ratios like 80% synthetic + 20% real are often tested, and even few-shot real data mixing has been shown to close the domain gap effectively in some tasks.
how this works


Two synthetic datasets of urban driving scenes—one generated with photorealistic ray-traced rendering, the other using simpler domain randomization—can be compared by training identical segmentation networks, such as DeepLabv3+ or SegFormer, and evaluating them on a real-world benchmark like KITTI or nuScenes.
The comparison can be quantified using metrics like mean Intersection-over-Union (mIoU), pixel accuracy, or class-wise F1 scores, revealing which simulation strategy better captures the features that matter for downstream perception tasks.
Robotics and Manipulation: For robotic grasp detection, synthetic datasets with varying lighting conditions, object textures, and clutter levels can be benchmarked by training a vision model and testing it on real-world camera feeds from the target robotic platform.
Grasp detection is particularly sensitive to depth cues and occlusion, making visual variety especially important. This is often evaluated in simulation-to-real transfer experiments, using benchmarks like RoboNet or YCB-Video (YCB-V) to assess how well the synthetic data prepares models for real-world grasping scenarios.
final thoughts
Synthetic data is no longer just a convenience; it’s rapidly becoming a critical enabler for scaling perception tasks at scale in computer vision systems. As models grow more complex and are deployed in increasingly unpredictable environments such as edge platforms like drones and mobile robots, the limitations of real-world data, including cost, rarity of edge cases, and annotation bottlenecks, make simulation and procedural generation indispensable.
But the path forward isn’t about blindly generating more synthetic data. As we’ve explored:
- Fidelity vs. scalability remains a fundamental trade-off—high-fidelity simulation reduces the sim-to-real gap but comes at high computational cost.
- Emerging technologies like GAN-based refinement for texture realism, procedural modeling for scalable scene variation, and RL-driven simulations for emergent behavior are making synthetic data more diverse, dynamic, and adaptive.
- Benchmarking and validation frameworks, using held-out real-world datasets, ensure synthetic datasets aren’t just visually impressive but actually improve downstream transfer performance.
- Closed-loop pipelines that adaptively generate data based on model weaknesses are bridging the last mile between simulation and deployment while reducing the total amount of synthetic data needed by focusing on high-impact, targeted generation.
Ultimately, the future of synthetic data for computer vision will be hybrid: a carefully engineered blend of physics-based simulation, generative AI, procedural diversity, and selective real-world data. This real-world component remains essential for anchoring realism, calibrating models, and validating performance against true environmental variability. The winning strategy won’t be about choosing simulation over reality but about orchestrating both to achieve the optimal balance of cost, coverage, and performance.
For engineers and data scientists, the challenge is clear: how do we design synthetic data pipelines that are computationally efficient, scientifically rigorous, grounded in measurable metrics and reproducible pipelines, and directly aligned with real-world deployment requirements? The answer lies in iterative, feedback-driven workflows where simulation quality is always anchored to measurable, benchmarked improvements.
As tools mature and validation standards become more robust, synthetic data will evolve from a niche tool into a core pillar of modern computer vision development. It is not just an optimization but a necessity for future vision systems, powering safer autonomous systems, enabling more intelligent robotics, and driving faster, more scalable AI innovation.
If you’re looking for high-fidelity synthetic training data for your computer vision application, learn more about Symage now!