Hybrid synthetic data, the practice of combining synthetically generated training data with real-world data, is quickly becoming the default approach for serious AI teams.
Models need more data, cleaner labels, better coverage, and more examples of rare edge cases. But real-world data is expensive to collect, slow to label, difficult to balance, and often incomplete.
That is why hybrid synthetic data approaches are gaining traction. Rather than relying on a single source, teams are combining synthetic and real-world data to get the best of both. Gartner has predicted that synthetic data will completely overshadow real data in AI models by 2030.
For computer vision teams, synthetic data can provide photorealistic images, controlled environments, and automatically generated pixel-level annotations. The SYNTHIA dataset, published at CVPR 2016 by Ros et al., contains 213,400 synthetic images with pixel-level annotations across 13 classes of urban scenes. The authors specifically demonstrated that combining SYNTHIA with real-world urban images significantly improved performance on the semantic segmentation task — not synthetic alone, but synthetic plus real (hybrid synthetic data).
The most effective teams are not treating synthetic data as a full replacement for real-world data. They are building hybrid synthetic data pipelines.
From “Synthetic vs. Real” to “Synthetic + Real”
The old question was: Can synthetic data replace real data?
The better question is: How can synthetic data and real-world data work together to improve model performance?
A 2025 study on hybrid synthetic data strategies found that the synthetic-to-real ratio of training data strongly influences ANN performance, and that “every increase in the real proportion leads to an improved performance.” A separate 2025 study on robotic suturing computer vision reported that synthetic-trained models alone could not generalize to real surgical scenarios, but a hybrid approach combining synthetic images with as few as 30–50 real annotated images achieved a Dice coefficient of 0.92.
The pattern is consistent across studies: synthetic data and real-world data complement each other. The goal is to reduce the domain gap, the performance drop that happens when a model trained in simulation encounters messy real-world conditions.
This matters because real-world datasets often underrepresent the very situations that matter most: unusual lighting, occlusion, rare object positions, uncommon defects, dangerous scenarios, class imbalance, and long-tail edge cases.
Synthetic data gives teams a way to intentionally generate the cases they are missing.
Why Pure Synthetic Data Can Fall Short
Synthetic data gives AI teams control. But control is not the same as reality.
Even well-designed synthetic data can miss subtle real-world variation: sensor noise, material behavior, shadows, reflections, background clutter, or unexpected object interactions.
That gap is well known in robotics and computer vision. Tobin et al. coined the term “domain randomization” in their 2017 paper, where they showed that randomizing simulated environments including textures, lighting, camera positions could make the real world appear to a model as “just another variation.” Using this approach, they trained a real-world object detector accurate to 1.5 cm using only simulated data with non-realistic random textures.
The lesson is important: synthetic data works best when it is designed for transfer, not just for volume. A million synthetic images are not automatically useful. They need to represent the right variations.
Where Synthetic Data Wins
Synthetic data is especially powerful in areas where real-world data is difficult, expensive, or unsafe to collect.
1. Perfect Labels at Scale
Semantic segmentation, object detection, pose estimation, and defect detection all depend on high-quality labels. But pixel-level labeling is labor-intensive.
A recent hybrid synthetic data pipeline for industrial part inspection generated 12,960 fully-annotated training images in roughly one hour, a labeling throughput that is simply not possible by hand.
For computer vision teams, this is one of synthetic data’s biggest advantages: labels are generated alongside the scene itself.
2. Edge Case Coverage
Real-world data is passive. You wait for the right conditions to happen.
Synthetic data is active. You create them.
Need more examples of a robot seeing an object at an unusual angle? Generate them. Need low-light scenes? Generate them. Need rare defects? Generate them.
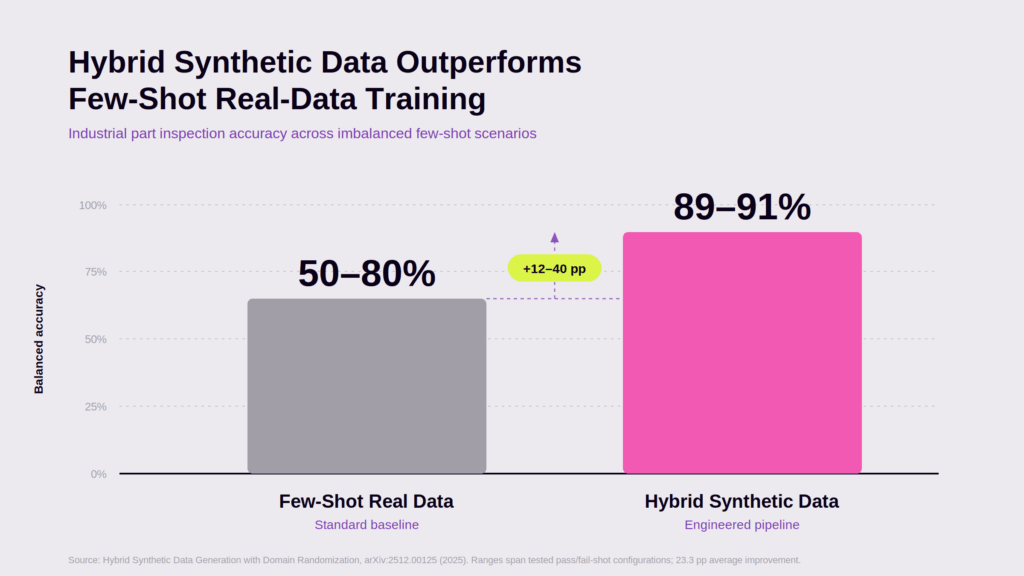
The same industrial inspection study found that a model trained on synthetic data with controlled class balance maintained 89–91% balanced accuracy under severe class imbalance (an 11:1 pass/fail ratio in real inspection data), while few-shot real-data baselines dropped to 50–80% under identical conditions, a 12 to 40 percentage-point improvement. For inspection, robotics, automation, and autonomous systems, that delta is the difference between a model that ships and one that does not.
3. Safer Testing and Training
Autonomous driving research has relied heavily on simulation because it allows teams to develop, train, and validate systems in controlled scenarios. CARLA, introduced by Dosovitskiy et al. at CoRL 2017, was built specifically to “support development, training, and validation of autonomous urban driving systems,” and has become a foundational tool in the field.
The same principle applies beyond autonomous vehicles. When real-world testing is expensive, dangerous, or impractical (think surgical robotics, industrial inspection of failure modes, defense scenarios) simulation becomes a practical training environment.
The Risk: Synthetic Feedback Loops
Synthetic data is not risk-free.
One of the biggest concerns in AI today is model collapse: what happens when models are repeatedly trained on data generated by other models.
A 2024 paper in Nature by Shumailov et al. (Nature 631:755–759) demonstrated that “indiscriminate use of model-generated content in training causes irreversible defects in the resulting models,” with the tails of the original data distribution disappearing over successive generations. The effect was observed across multiple model families, including LLMs, variational autoencoders, and Gaussian mixture models.
Gartner’s 2025 D&A predictions echoed the operational risk: 60% of data and analytics leaders will face critical failures managing synthetic data by 2027, risking AI governance, model accuracy, and compliance.
For AI teams, the takeaway is not “avoid synthetic data.”
The takeaway is: avoid synthetic data without lineage, validation, and real-world anchoring.
Synthetic data should be part of a controlled training strategy, not an uncontrolled feedback loop.
The Winning Approach: Hybrid synthetic Data Pipelines
The best hybrid synthetic data strategy is iterative.
Step 1: Start with real-world data. Use it to understand the operating environment — object appearance, lighting conditions, camera behavior, common failure modes, deployment constraints.
Step 2: Identify gaps. Where does the model struggle? Glare conditions, partial occlusion, underrepresented rare classes? These gaps should drive synthetic data generation.
Step 3: Generate targeted synthetic data. Synthetic data should be generated with purpose — rare classes, unusual poses, environmental variation, defects, safety-critical scenarios, hard negatives — not generic volume.
Step 4: Train on hybrid synthetic data. Mixed synthetic-real training research consistently shows that combining synthetic variation with real-world authenticity improves generalization. The exact ratio varies by use case. The important part is to treat the dataset as an engineered system, not a static asset.
Step 5: Validate against real-world performance. Synthetic validation alone is not enough. The final test is whether the model performs better in the real world. That means real-world holdout sets, benchmark tasks, and ongoing monitoring after deployment.
Synthetic Data Is Becoming ML Infrastructure
The bigger shift is that synthetic data is no longer just a workaround for missing data. It is becoming part of the AI training stack, supporting faster dataset creation, automated labeling, edge case generation, model robustness testing, privacy-safe data sharing, and simulation-based validation.
But the value does not come from synthetic data alone. It comes from using a hybrid synthetic data approach.
Final Thought
Synthetic data is not a shortcut around reality. It is a way to train for more of it.
The strongest AI teams will not be the ones with the biggest datasets. They will be the ones with a hybrid synthetic data strategy: real data to ground the model, synthetic data to expand coverage, and continuous validation to make sure performance transfers.
That is the new reality of AI training.
Want to See What High-Fidelity Synthetic Data Can Do?
At Symage, we help AI teams create photorealistic synthetic image data with precise pixel-level labels, built for real-world training pipelines. Whether you are working on robotics, automation, inspection, or computer vision, synthetic data can help you fill the gaps real-world data leaves behind.